



Introduction
Least Recently Used (LRU) cache organizes recently added/accessed items at the front of the list while pushing the least used items to the back. The number of items that can be stored in the LRU cache is fixed, thus least used item is evicted from the cache while adding a new item when the cache is already full. This cache allows quickly identifying the least used item in O(1) time. Also, the addition, retrieving, and deletion of items is O(1) time on average.
To understand the algorithm of LRU cache, visualize a rack of clothes, in which new clothes and used clothes are always hung from the right-most end of the row. Now we can identify which clothes aren't used for a long time, as they are always at the left end.
Implementation
In the cache data structure, we should be able to save data with an associated key, which later can be used to access data from the cache. This means we can use a map[string]interface{} data structure to store key-value pairs.
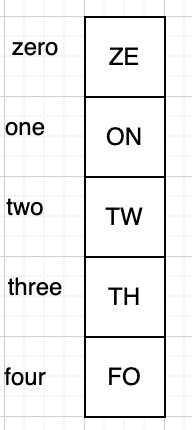 Using
Using map[string]interface{} have the following benefits:
- Can store and retrieve data in O(1) time complexity.
- We can reference data by using a key.
- We can store any data structure regardless of its type.
If we remember the characteristics of the LRU cache, map neither has a fixed size nor it can maintain the object order in any way. So it isn't sufficient for implementing the LRU cache. One of the ways to resolve this issue is to add an array of fixed lengths to the equation. Now we can make a slight change in the data storage approach. We would store data in the array and its key and index in the map as shown below.
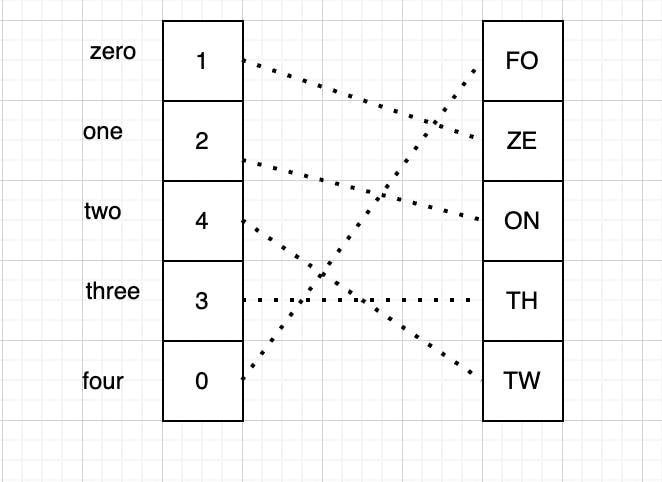
Adding an array to the equation solves our two problems: An array has a fixed size and we can maintain the order of items with the latest added/accessed items at the start and the
oldest ones at the end of the array. We just need to fill up the items from the opposite direction. When the array is full, we would delete the item at the tail of the array, increase the indexes of every remaining item, and then add a new item at the first position of the array. Now we can see a problem here, adding an array would have O(n) complexity in the worst case while writing and accessing the data from an array.
To make our cache faster we would need a data structure that allows us to access and arrange items in O(1) time. Adding a double-linked list would resolve this problem. Now we have to save the key and a pointer to the node in the linked list in the map and the data itself in the list.
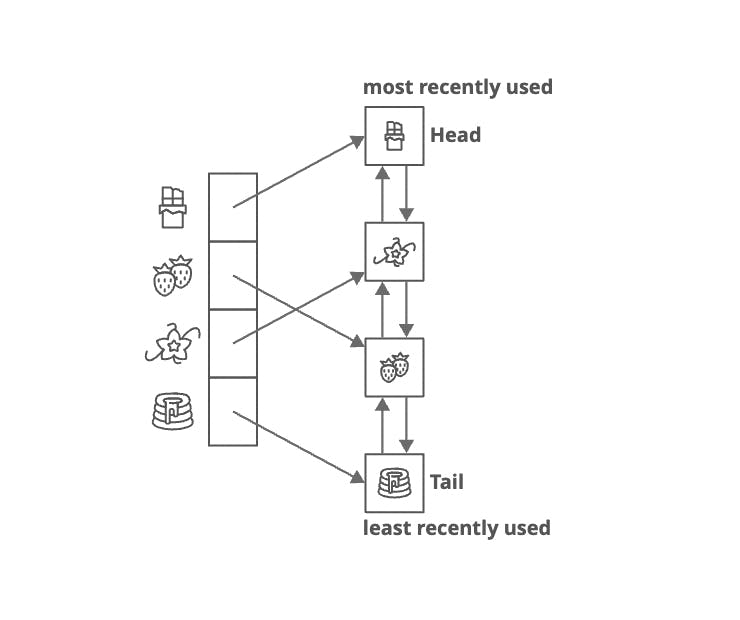
Now if we have to add data into the cache we would add it to the head of the linked list, and remove data from the tail of the linked list.
Coding
For implementing the LRU cache in the Go, we would first define a node struct that holds the data and can form a chain by pointing to previous and next nodes.
type Node struct {
Key string
Value interface{}
next, previous *Node
}
Another struct we would need is a Cache struct with following properties.
type Cache struct {
capacity int
size int
head, tail *Node
index map[string]*Node
}
The capacity of the cache would determine the maximum number of data elements the cache would hold, size means the current number of elements in the cache, the index is the map holding key and reference to the node holding the value, head and tail are two nodes that determine the sequence of data.
Initializing Cache
We first initialize the cache with its capacity and size 0; the head and tail reference each other in such a way that the previous pointer of the tail points to the head and the next pointer of head points to the tail.
func NewCache(capacity int) *Cache {
head := NewNode().Set("head", true)
tail := NewNode().Set("tail", true).SetPrevious(head)
head = head.SetNext(tail)
return &Cache{
capacity: capacity,
size: 0,
head: head,
tail: tail,
index: make(map[string]*Node),
}
}
Adding data to the cache
While adding data we would look if the key already exists in the cache. If the key is present then we would remove existing data from the linked list. Next, we would check if the cache is full. In case the cache is full then we would remove an item from the tail. Then the new item is added next to the head in the linked list.
func (cache *Cache) Put(key string, value interface{}) {
if cache.IsFull() {
cache.remove(cache.tail.previous)
}
node, ok := cache.index[key]
if ok {
cache.remove(node)
}
newNode := NewNode().
Set(key, value).
SetPrevious(cache.head).
SetNext(cache.head.next)
cache.head.next.SetPrevious(newNode)
cache.head.SetNext(newNode)
cache.index[key] = newNode
cache.size += 1
}
Reading Data from Cache
While reading data we first check if the key is present in the index map. If it's not available cache miss is returned. If the data is present then the data node is moved to the next of head in the linked list and the value held in the node is returned.
func (cache *Cache) Get(key string) (interface{}, bool) {
node, ok := cache.index[key]
if !ok {
return nil, false
}
cache.remove(node) // remove from old position
newNode := node.Clone().SetPrevious(cache.head).SetNext(cache.head.next)
cache.head.next.SetPrevious(newNode)
cache.head.SetNext(newNode)
cache.size += 1
return newNode.Value, true
}
Evicting Node from Cache
While removing data from the cache, node reference is obtained from the index map. Then the adjacent nodes are referenced to each other and the node is set as null.
func (cache *Cache) Delete(key string) {
node, ok := cache.index[key]
if !ok {
return
}
cache.remove(node)
}
func (cache *Cache) remove(node *Node) { //TODO: return error
if node == nil || node.IsHead() || node.IsTail() {
return
}
if node.previous != nil {
node.previous.SetNext(node.next)
}
if node.next != nil {
node.next.SetPrevious(node.previous)
}
delete(cache.index, node.Key)
if cache.size > 0 {
cache.size -= 1
}
}
The complete LRU cache implementation can be found in this repo.